前言
人类对计算机视觉感兴趣的最重要的问题是图像分类 (Image Classification)、目标检测 (Object Detection) 和图像分割 (Image Segmentation),同时它们的难度也是依次递增。
在分类任务 (Image Classification) 中,我们只关注图片中物体的类别。
目标检测 (Object Detection) 任务不仅要识别出图片中物体的类别,同时还要知道这些物体各自在什么地方,使用bounding box将这些目标框出
而图像分割 (Image Segmentation) 任务跟目标检测任务其实有一定的相似,都是识别图片中的物体并在图片中标注出物体的位置。
只不过不再是用bbox来框出物体,而是精确到像素级,需要准确的知道物体的边缘在什么地方。通过下方的左右两张图片我们可以很明显地看出目标检测与图像分割的区别。
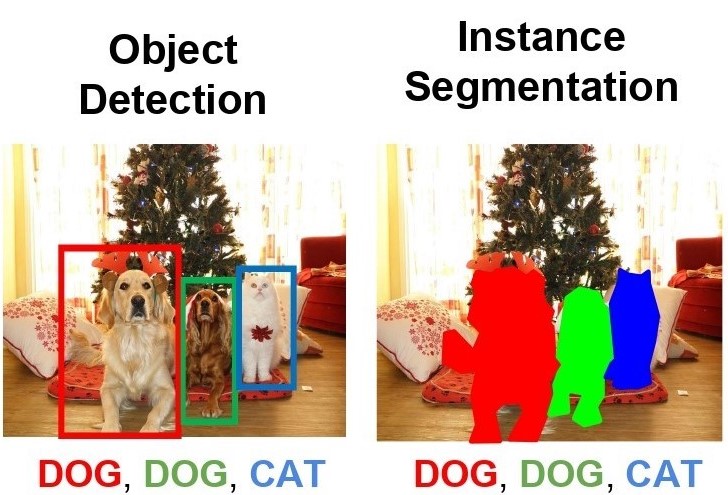
Source CS231n: Deep Learning for Computer Vision(2017) Lecture 11. This image from CC0 public domain
什么是图像分割
一张图片是由一堆像素构成的,图像分割 (Image Segmentation) 可以理解成对每一个像素进行分类的任务。
有两种最常见的图像分割技术:语义分割 (Semantic Segmentation) 和实例分割 (Instance Segmentation)。
语义分割时,在一张图片中有多个同一类物体的时候,同类别两个物体不用被明确的区分开,他们的像素标签都会是同一类别。
而实例分割时,当一张图片中有多个同一类物体时,不仅需要识别出物体的类别,还需要把两个同类物体给区分开。
如上图所示,在进行语义分割的时候,左边的两只狗会被分为同一类,用同一种颜色表示;而在实例分割的时候,左边的两只狗会被用不同颜色区分开,即这两只狗的上的像素的标签为不同类。
在看下面这张图。图 (b) 就是语义分割,途中的多辆汽车被分为了同一类,用同一种颜色表示;而图 (c) 是实力分割,虽然有多辆车,但是他们的标签类别却是不一样的,被用不同的颜色标记出来。
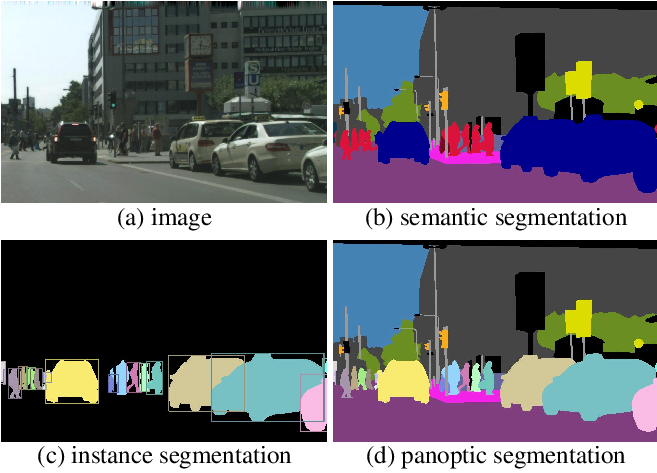
Source Panoptic Segmentation
图 (d) 是全景分割 (panoptic segmentation)
对于给定图片 (a) 各任务的groundtruth分别是
- 图 (b) 的语义分割是逐像素的 class labels;
- 图 (c) 的实例分割是逐 object 的 mask 和 class label;
- 图 (d) 的全景分割是逐像素的 class labels 和 instance labels。 全景分割同时完成语义分割和实例分割任务,需要对图片中的每一个可见 object 和 region 进行辨别与描述。
全景分割与实例分割,语义分割的不同:
- 对比语义分割,全景分割需要区分不同的 object instances;
- 对比实例分割,全景分割不仅分割things(即实例分割中的object),同时分割stuff(指具有相似纹理或材料的无定形区域,例如草、天空、道路。);
- 全景分割需要同时识别 stuff 和 things。
本博客主要将以语义分割为主。
图像分割的应用
图像分割的应用有很多,下面举了几个图像分割在现实生活中的应用
医学影像诊断
通过对MRI,CT,X光等医学影片进行图像分割,可以辅助医生诊断,甚至可以定位到病灶给出诊断结果。如下图,左边第一张图是大脑的MRI原图,右边两张是进行图像分割后的图片。

Source A Survey of Current Methods in Medical Image Segmentation
再比如这张胸片,通过图像分割后,可以很清晰的分辨出肺、锁骨和心脏的位置。
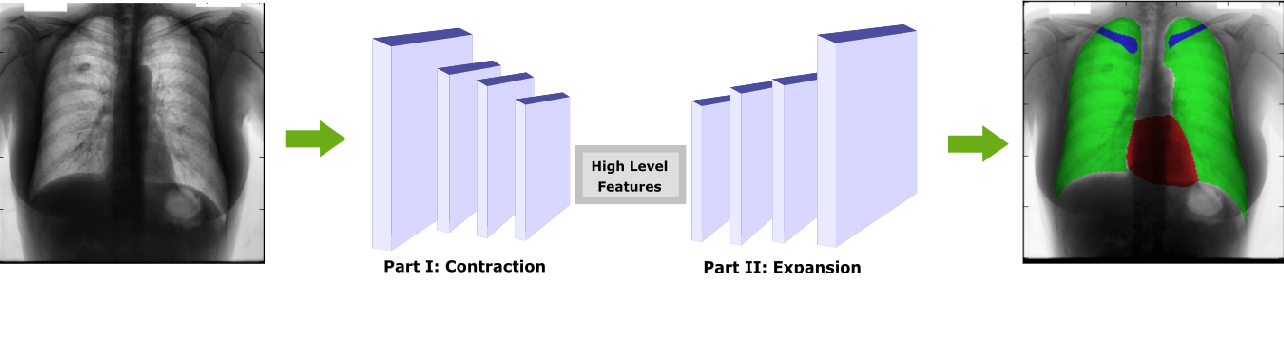
Source Fully Convolutional Architectures for Multi-Class Segmentation in Chest Radiographs
自动驾驶
图像分割最著名的应用是自动驾驶。图像分割可以帮助汽车通过摄像头分辨路面、路牌、行人与车辆。如果是较为粗略的目标检测的话,很难胜任安全要求较高的自动驾驶任务。

Source Semantic segmentation — Udaity’s self-driving car engineer nanodegree

Source Tensorflow DeepLab v3 Xception Cityscapes
自动扣图
图像分割可以把每个物体所在位置的像素给分别标注出来,这跟抠图任务很类似。比如把一张商品的图片输入模型,通过图像分割可以分辨出哪些像素属于背景,哪些像素属于前景(商品)呢?

Source XuHao
虚拟试穿
最后一个我们生活中有遇到过的运用。在某些购物APP上有3D试穿功能。就是选择好想试穿的衣物,通过手机摄像头对准要试穿的身体部位,手机上就会呈现出穿上这一衣物的样子。

Source Toward Characteristic-Preserving Image-based Virtual Try-On Network
这其实也是需要通过图像分割来分割出我们身体上应该穿上衣服的部位的。
同时,还有一种虚拟化妆的任务,其实原理也跟虚拟试穿类似。
Reference
- Anil Chandra Naidu Matcha. “A 2021 guide to Semantic Segmentation.” https://nanonets.com/blog/semantic-image-segmentation-2020/
- Jeremy Jordan. “An overview of semantic image segmentation.” https://www.jeremyjordan.me/semantic-segmentation/
- Fei-Fei Li & Justin Johnson & Serena Yeung. “CS231n: Deep Learning for Computer Vision.” (2017). Lecture11. http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
- Pham, Dzung L. et al. “A Survey of Current Methods in Medical Image Segmentation.” (1999).
- Novikov, Alexey A., et al. “Fully convolutional architectures for multiclass segmentation in chest radiographs.” IEEE transactions on medical imaging, 37.8 (2018): 1865-1876.
- Dhanoop Karunakaran. “Semantic segmentation — Udaity’s self-driving car engineer nanodegree.” https://medium.com/intro-to-artificial-intelligence/semantic-segmentation-udaitys-self-driving-car-engineer-nanodegree-c01eb6eaf9d
- Wang, Bochao, et al. “Toward characteristic-preserving image-based virtual try-on network.” Proceedings of the European Conference on Computer Vision (ECCV). 2018.
「如果这篇文章对你有用,请随意打赏」
 Hao Xu Blog
Hao Xu Blog如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付
